很多新手建站朋友对robots协议文件的重要性不是很清楚,本篇文章由昆明SEO博主普及一下 WordPress站点robots协议文件编写知识。robots协议(也称为爬虫协议、机器人协议 等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。robots协议主要注意以下几大方面:
一、使用robots协议需要注意的几点地方:
1、指令区分大小写,忽略未知指令。
2、每一行代表一个指令,空白和隔行会被忽略。
3、“#”号后的字符参数会被忽略。
4、有独立User-agent的规则,会排除在通配“*”User agent的规则之外。
5、可以写入sitemap文件的链接,方便搜索引擎蜘蛛爬行整站内容。
6、尽量少用Allow指令,因为不同的搜索引擎对不同位置的Allow指令会有不同看待。
7、robots.txt 文件必须放在网站的根目录,不可以放在子目录。
二、robots协议文件写法:

1、User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
2、Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
3、Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
4、Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
5、Disallow: /cgi-bin*/trackback //屏蔽wordpress分类目录、文章页面的回评路径
11、Disallow: /feed //屏蔽wordpress的内容订阅路径
12、Disallow: feed //屏蔽wordpress分类目录、文章页面的订阅路径
13、Disallow: /comments/feed //屏幕wordpress评论的订阅路径
14、Disallow: /page/ //屏蔽默认的翻页路径
15、Disallow: page/ //屏蔽分类目录的翻页路径
16、Disallow: /page/1$ //屏蔽翻页路径中的数字路径
17、Disallow: /tag/ //屏蔽标签页面
18、Disallow: /?s=* //屏蔽搜索结果路径,主要是避免搜索结果的缓存被搜索引擎收录
19、Disallow: /date/ //屏蔽按日期分类显示的列表页面
20、Disallow: /author/ //屏蔽作者文章列表页面
21、Disallow: /category/ //屏蔽以category为起始路径的分类路径,如果您没有使用插件生成不带category前缀的路径时,请不要使用此项规则。
22、Disallow: /wp-login.php //屏蔽后台登陆页面
四、robots协议设置方法
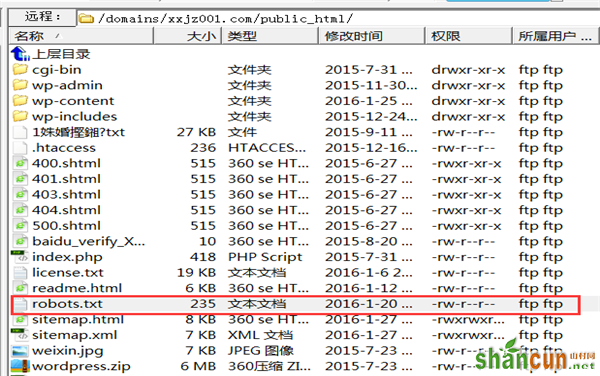
1、写好之后把文件重命名为:robots.txt 然后用FTP上传到网站的根目录下面,切记不是主题的根目录下而是网站的根目录。
2、利用站长工具自动生成,网址:http://tool.chinaz.com/robots/
3、利用SEO插件设置,比如Yoast SEO、all in one seo
五、robots协议的作用
1、引导搜索引擎蜘蛛抓取指定栏目或内容;
2、网站改版或者URL重写优化时候屏蔽对搜索引擎不友好的链接;
3、屏蔽死链接、404错误页面;
4、屏蔽无内容、无价值页面;
5、屏蔽重复页面,如评论页、搜索结果页;
6、屏蔽任何不想被收录的页面;
7、引导蜘蛛抓取网站地图;
六、如何查看robots协议:
1、WordPress站点默认在浏览器中输入:http://你的域名/robots.txt
比如星辰seo博客:http://xxjz001.com/robots.txt
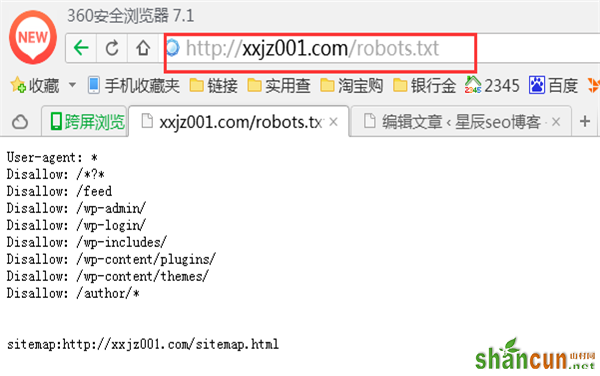
2、打开FTP,找到网站根目录查看robots.txt文件
总结:robots协议需要的注意地方,以及写法,设置方法,作用,如何查看就介绍到这里,相信大家对robot协议已经有了比较详细的了解。使用 好robots协议对于我们网站的SEO有着重要作用,做的好可以有效的屏蔽那些我们不想让搜索引擎抓取的页面,也就是对用户体验不高的页面,从而将有利 于关键词排名的内页充分展示个客户,获得搜索引擎对站内页面的权重,从而有利于我们将网站关键词排名做的更好,从而获取更多流量。
作者:星辰seo博客