如果一个类只定义了类名,没定义任何方法和字段,如class A{};那么class A的每个实例占用1个字节的内存,编译器会会在这个其实例中安插一个char,以保证每个A实例在内存中有唯一的地址,如A a,b;&a!=&b。如果一个直接或是间接的继承(不是虚继承)了多个类,如果这个类及其父类像A一样没有方法没有字段,那么这个类的 每个实例的大小都是1字节,如果有虚继承,那就不是1字节了,每虚继承一个类,这个类的实例就会多一个指向被虚继承父类的指针。还有一点值得说明的就是像 A这样的类,编译器不一定会产生传说中的那6个方法,这些方法只会在需要的时候产生,如class A没有被任何地方使用那这些方法编译器就没有必要产生,如果这个类实例化了,那么会产生default constructor,而destructor则不一定产生。
如果一个类中有static data member,nonstatic data member,还有const data member,enum,那么它的内存布局会是什么样的呢,看下面简单的类Point:
class Point
{
public:
Point():maxCount(10){}
private:
int X;
static int count;
int Y;
const int maxCount ;
enum{
minCount=2
};
};
Sizeof(Point)=12, 为什么占12字节呢,我相信很多人都知道是哪几个成员变量占用的,就是X,Y,maxCount,maxCount作为常量字段,但在Point的每个实 例中可能有不同的值,当然属于Point实例的一部分,如果把maxCount定义成static,那它就不不是Point实例的一部分了,如果定义成 static const int maxCount=1;则maxCount分配在.data段中,如果没有初始化则分配在.bss段中,反正跟Point的实例无关,count分配 在.bss段中,minCount分配在.rdata段中,总之count,maxCount,minCount在编译连接完成之后,内存(虚拟地址)就 分配好了,在程序加载的时候,会把他们的虚拟地址对应上实际的物理地址。
Data member的内存布局:nonstatic data member在class object中的顺序和其申明的顺序一样,static data member和const member不在class object中因为他们只有一份,被class object共享,所以static data member和const data member,枚举并不会响应class object的大小。关于段的信息,我觉得是每个C/C++程序员必须知道的。而Point每次实例化的时候则只需要分配X,Y,maxCount需要的 内存。
每个类的data member在内存中应该是连续的,如果出现数据对齐的情况,可能中间会有空白地带。请看下面几个类:
class AA
{
protected:
int X;
char a;
};
class BB:public AA
{
protected:
char b;
};
class CC:public BB
{
protected:
char c;
};
Sizeof(AA)=8//对齐3字节
Sizeof(BB)=12//两个3字节对齐
Sizeof(CC)=16//编译器“无耻”的用了3个3字节对齐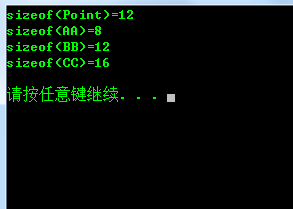
编 译器为什么要无耻的在class CC中加3个3字节对齐呢,这样每个CC的实例就大了9字节。如果编译器不加这9字节的空白,那么CC的每个实例就是8字节,前面的X占4字节,后面的 a,b,c占3字节,加1字节的空白对齐,刚好8字节,没有谁很傻很天真的以为最好是占7字节吧。
如果CC占用8字节内存,同样的AA,BB都是8字节的内存,这样的话,如果把一个指向AA实例的指针赋给一个指向CC实例的指针,那么就会把AA中的8字节直接盖到CC的8字节上,结果CC实例中的b,c都被赋上了不是我们想要的值,这很可能会导致你的程序出问题。
父类的data member会在子类的实例中有完整的一份,这样在有继承关系的类之间进行类型转换,就只用简单的修改指针的指向。
Data Member的存取。对一个data member的存取,编译器把对象实例的起始地址加上data member的偏移量。如CC c;
c.X=1;相当于&c+(&CC::X-1),减一其实是为了区分是指向object的指针还是指向data member的指针,指向data member的要减一。每一个data member的偏移量在编译的时候是知道的,根据成员变量的类型和内存对齐,存在virtual继承或是虚方法的情况编译器会自动加上一些辅助的指针,如 指向虚方法的指针,指向虚继承父类的指针等。
在data member的存取效率上,struct member 、class member、单一继承或是多重继承的情况下效率都是一样的,因为他们的存储其实都是&obj+(&class.datamember- 1)。在虚继承的情况下,可能会影响存储性能,如通过一个指针来存取一个指向虚继承而来的data member,那么性能会有影响,因为在虚继承的时候,在编译的时候还不能确定这个data member是来自子类还是父类,只有在运行的时候才能推断出来,其实就是多了一步指针的操作,在虚继承中,如果是通过对象实例来操作虚继承而来的 data member,则不会有任何性能问题,因为不存在什么多态性,所有东西在编译的时候内存地址都确定了。
虚继承还是虚方法为了实现多态一样,多了一步,如果不需要多态,而是通过对象实例调用相关的方法就不会有性能问题。